7 服务质量(Quality of Service, QoS)
上一章
上一章讨论了流量控制协议(Flow Control)的目的及其详细操作。流量控制用于确保发送端不会发送接收端无法接收的事务层包(Transaction Layer Packet, TLP),从而避免接收缓冲区溢出,并消除传统 PCI 机制中的低效行为,例如断开(disconnect)、重试(retry)和等待态(wait-state)。
本章
本章讨论支持服务质量(Quality of Service, QoS)的相关机制,并说明如何控制穿越 PCIe 结构(fabric)的不同数据包的传输时机和带宽。这些机制包括:由应用相关软件为每个数据包分配优先级,以及在每个设备中实现可选硬件,以支持事务优先级管理。
下一章
下一章将讨论 PCIe 拓扑中的事务排序要求。这些规则继承自 PCI,其中许多规则源于“生产者/消费者(Producer/Consumer)”编程模型,因此下一章会先介绍该模型的工作机制。原始排序规则还考虑了必须避免的潜在死锁情况。
7.1 QoS 的出发点(Motivation)
如今的许多计算机系统并不包含用于管理外设流量的机制,但是有一些应用是需要这种机制的。举一个例子,流媒体视频通过一个通用数据总线(general-purpose data bus)传输,这要求数据要在正确的时间传输。在嵌入式引导控制系统中,及时的传输视频数据对于系统操作来说也是极为关键的。由于预见到了这些需求,原始 PCIe 规范中就包含了 QoS(服务质量)机制,它可以使得某些流量更优先被传输或处理。更广义的说法是,这是一种差异化的服务(Differentiated Service),因为数据包会根据被分配的的优先级不同而受到不同的处理对待,并且这种机制允许有一个范围较广的服务偏好级别(也就是允许的优先级比较多)。在这个范围的较高等级,QoS 机制可以为这个优先级的应用提供可预测的(Predictable)以及可保证的(Guaranteed)的性能。这种级别的服务支持被称为“Isochronous(等时)”服务(可以类比同步以太网、TTE,这里的 Isochronous 就是这个同步的含义),这个术语来源于两个希腊单词“isos”(相等)和“chronos”(时间),合起来就表示某个事情以相同的时间间隔发生。要使得这样的机制在 PCIe 中能正常工作,这要求硬件元素和软件元素的共同作用。
7.2 基本元素(Basic Elements)
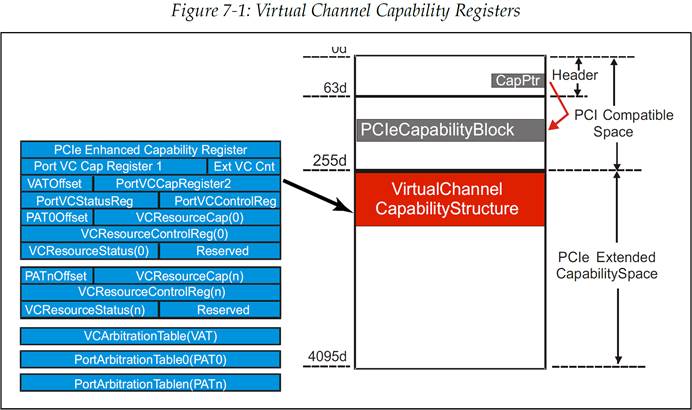
支持高级别的服务给系统性能提出了一些要求。例如,传输速率需要足够高,这样才能满足应用在一个时间范围内传输足够多的数据的需求,同时这也使得应用能够适应与其他流量之间的竞争。另外,传输时延也需要足够低,这样才能确保数据包及时到达,避免出现延迟问题。最后,必须要对错误处理进行管理,这样它才不会影响到需要及时传输的数据包的传输。要实现上述这些目标,需要有一些特殊的硬件元素,其中一种就是一组称为虚拟通道能力块(Virtual Channel Capability Block)的配置寄存器组,如图 7-1 所示。
图 7-1:虚拟通道能力寄存器
7.2.1 流量类别(Traffic Class, TC)
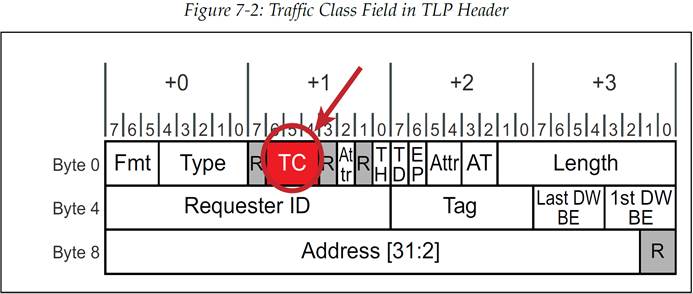
我们所需要的第一件事情是要用一种方式来区分各种流量,也就是需要用一些东西来区分哪些数据包具有高优先级。这种需求是通过为数据包标明流量类别(TC)来完成的,流量类别(TC)中定义了 8 个优先级,它通过 TLP 头部中的 3 bit TC 字段来表示(TC0-TC7,数字越大优先级越高)。图 7-2 所示的 32 位 Memory 请求的 TLP 头部中标识出了 TC 字段的位置。在初始化过程中,设备驱动程序会与同步管理软件(Isochronous Management software)沟通服务级别,同步管理软件会返回相应的 TC 值供各类数据包使用。然后驱动程序就会给数据包分配正确的 TC 优先级。TC 值默认为 0,这样就可以让不需要高优先级服务的数据包不会干扰到那些需要高优先级服务的数据包。
图 7-2:TLP 头部中的流量类别(TC)字段
不识别 PCIe 的配置软件(指传统 PCI 的配置软件)是无法识别出这些新的寄存器的,它就会为所有的事务都分配默认的 TC0/VC0。另外,也有一些数据包一直被要求要使用 TC0/VC0,比如配置(Configuration)、I/O 以及 Message 事务。如果这些数据包被认为是维护包流量,那么就有必要将它们限制在 VC0 中,并且要让它们远离高优先级数据包的传输路径,避免影响到高优先级包。
7.2.2 虚拟通道(Virtual Channel, VC)
VC(虚拟通道)实际上是硬件缓冲区,它用来作为输出数据包的队列。每个端口都必须要包含默认的 VC0,并且最多可以有 8 个 VC(VC0-VC7)。每个通道都表示可供输出数据包使用的不同传输路径。使用多通道路径的想法类似于收费公路,如果司机购买了某种无线电标签,那么收费站就允许他们在高优先级车道行驶,而对于那些没有购买无线电标签的司机来说,虽然他们仍然可以在这条收费公路行驶,但是他们必须在每个收费站都停下来,且每次通过都要付钱,这使得这些司机通过收费站需要更长的时间。如果只有一条路径,那么要经过的每个人所花费的时间将受到最慢的那个司机的影响和延误,而如果有多条路径的话就意味着有高优先级的司机不会被延误(可以使用高优先级通道)。
7.2.2.1 为每个 VC 分配 TC————TC/VC 映射
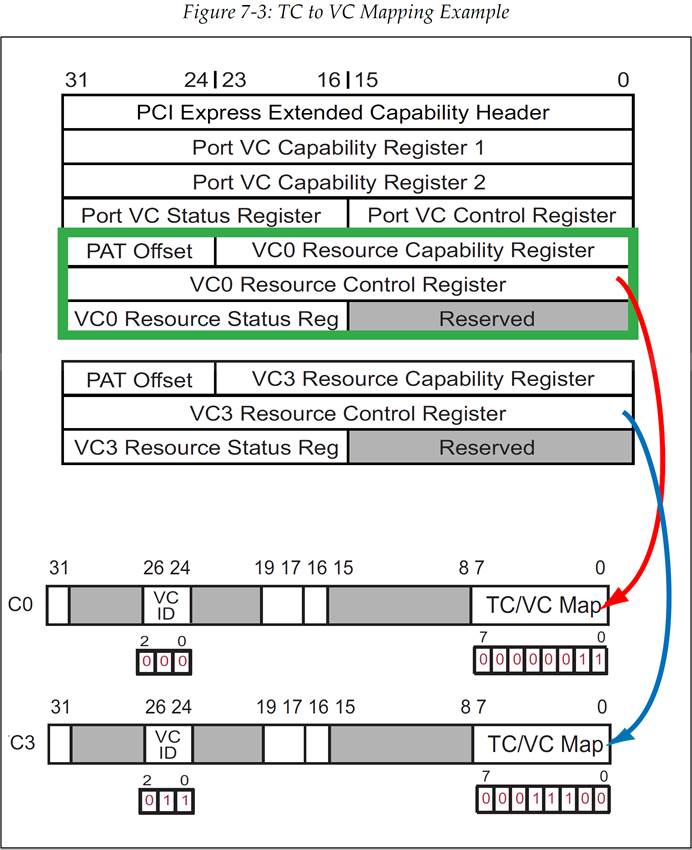
分配给每个数据包的 TC 值在整个传输过程中是不会改变的,而且必须在每个服务点都有 TC 对 VC 的映射,也就是某种 TC 的数据包要使用哪条路径传输到目的地。VC 映射是链路自己指定的,从一个链路到另一个链路后 VC 映射是可以改变的。配置软件会在初始化时建立这种映射关系,它是通过 VC 资源控制寄存器(VC Resource Control Register,图 7-1)中的 TC/VC Map 字段来实现的。这个 8 bit 的字段使得多个 TC 值可以被映射到某一个 VC,因为它的每个 bit 都代表了一个对应的 TC 值(bit 0 = TC0,bit 1 = TC1,etc.)。将一个 VC 的 8 bit TC/VC Map 字段中的某一位置为 1,就表示将相应的 TC 分配给了这个 VC。图 7-3 展示了一个 TC/VC 的映射例子,这个例子中 TC0 和 TC1 被映射到了 VC0,而 TC2、TC3、TC4 则是映射到了 VC3。
软件在分配 VC ID 和映射 TC 的方面有很大的灵活性,但是在进行 TC/VC 映射时也要遵循一些规则:
对于相同的一条链路的两端的两个端口来说,它们的 TC/VC 映射必须是相同的。
TC0 自动映射到 VC0。
其他的 TC(除了 TC0)可以映射到任何一个 VC。
一个 TC 只能映射到一个 VC,而可以有多个 TC 映射到同一个 VC。
所使用的虚拟通道的数量取决于链路两端设备所能共享的最大虚拟通道资源容量。软件会为每个 VC 分配 ID,并且会将 TC 映射至 VC。
图 7-3:TC 到 VC 的映射举例
7.2.2.2 确定要使用的 VC 数量
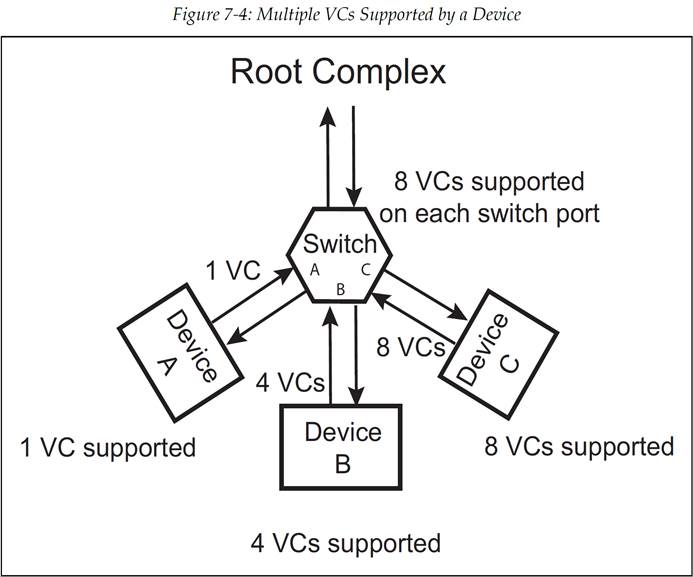
软件会检查连接在公共链路上的设备所能支持的 VC 的数量,并且一般会选择链路两端设备所能支持的最大数量作为 VC 的实际使用数量。考虑如图 7-4 所示的拓扑示例,在这里,交换机上的每个端口(port)都支持全部的 8 个 VC,而设备 A 仅支持默认的 VC0,设备 B 支持 4 个 VC,设备 C 支持 8 个 VC。需要注意,虽然交换机的端口 A 能够支持 8 个 VC,但是由于设备 A 仅能支持 VC0,因此端口 A 的其余 7 个 VC 是无法被使用的。相似地,交换机的端口 B 实际也仅能使用 4 个 VC。
图 7-4:一个设备支持多个虚拟通道
配置软件要确定每个端口所能支持的最大 VC 数量,它是通过读取虚拟通道能力寄存器组(Virtual Channel Capability register,图 7-1)中的 Extended VC Count 字段来完成的,这个字段如图 7-5 所示。
图 7-5:扩展 VC 支持字段

7.2.2.3 分配 VC ID
配置软件需要给每个 VC 都分配一个 ID 号,除了 VC0(因为它是固定存在的)。如图 7-3 所示,VC 能力寄存器空间中,每个 VC 都有自己 12 Byte 的配置寄存器组。第一组寄存器总是由 VC0 使用。扩展 VC 计数(Extended VC Count)字段定义了当前端口实现的额外 VC 的数量(除 VC0 之外),每个实现的 VC 都有一组配置寄存器。注意,字段的值“n”表示的是额外实现的 VC 的数量,例如扩展 VC 计数字段为 3,那么就说明除了 VC0 以外还有 3 个 VC,以及它们每个都有一组自己的配置寄存器。
软件通过使用 VC ID 字段为每个额外的 VC 分配一个编号(见图 7-3)。这些 ID 号并不一定要是连续的,但是必须只能出现一次而不能重复。
7.3 VC 仲裁(VC Arbitration)
7.3.1 概述(General)
当一个设备有多个 VC,且每个 VC 都有待发送的数据包,那么就需要 VC 仲裁机制来决定数据包传输的顺序。软件可以从硬件所实现的几种选择方案中选择任意的一种。设计的目标是要实现所需的服务策略,并且确保所有的事务都在向前推进,以防止发生意外超时。另外,VC 仲裁也会受到流量控制(flow control)和事务排序(Transaction Ordering)的相关需求的影响。这些主题内容将在其他章节中讨论,但是要注意它们也会影响仲裁,因为:
每个受支持的 VC 都有它自己的缓冲区和流控处理
映射到同一个 VC 的多个事务一般会按照严格的顺序传输(尽管也有例外,比如一个数据包的“宽松排序 Relaxed Ordering”这一属性标志位被置为 1 时。)
事务排序(Transaction Ordering)仅应用在一个 VC 内,因此对于分配给不同的 VC 的几个数据包之间是不存在排序关系的。
图 7-6:中的例子中包含两个 VC(VC0 和 VC1),VC1:VC0 的传输优先级是 3:1 的比率,也就是说每传输 3 个 VC1 数据包才会发送 1 个 VC0 数据包。设备核心(Device Core)向 TC/VC 映射逻辑发送请求(请求包中包含 TC 值)。基于已经规划好的映射,数据包被放入相应的 VC 缓冲区中等待传输。最终,VC 仲裁器决定由哪个 VC 优先发送数据包。这个例子展示了一个单向的流程,但是同样的逻辑也适用于同时进行相反方向的传输。
VC 能力寄存器提供了三种基本的 VC 仲裁方式:
严格优先级仲裁(Strict Priority Arbitration):在所有包含数据包的 VC 中,拥有最高编号的 VC 永远赢得仲裁。
分组仲裁(Group Arbitration):VC 被硬件分成 1 个低优先级组和 1 个高优先级组。低优先级组使用的仲裁方法是由软件从可选方法中来选取的,而高优先级组则是使用严格优先级仲裁(Strict Priority Arbitration)。
硬件固定仲裁(Hardware Fixed arbitration):仲裁方案构建在硬件中。
图 7-6:VC 仲裁示例
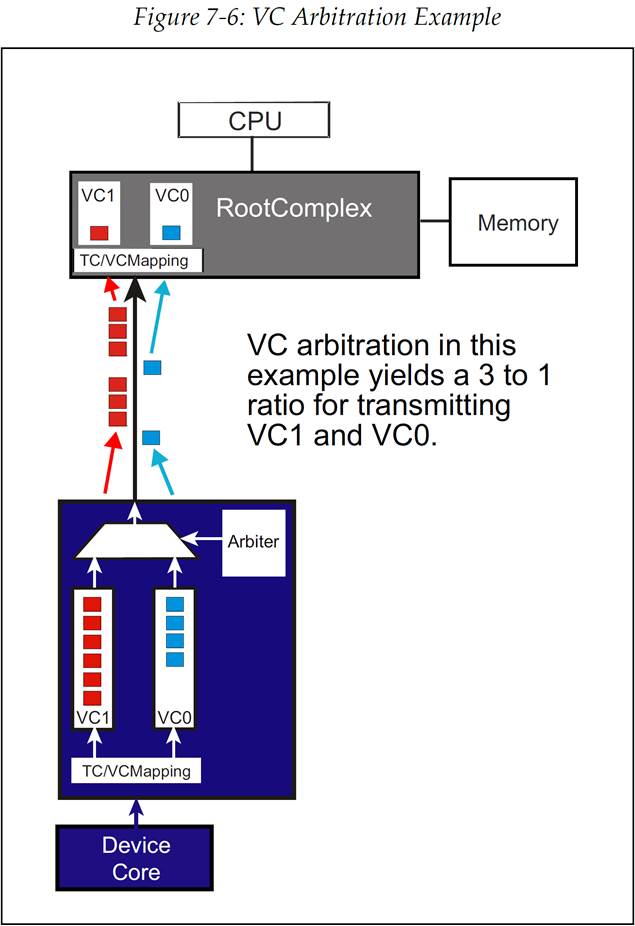
7.3.2 严格优先级 VC 仲裁(Strict Priority VC Arbitration)
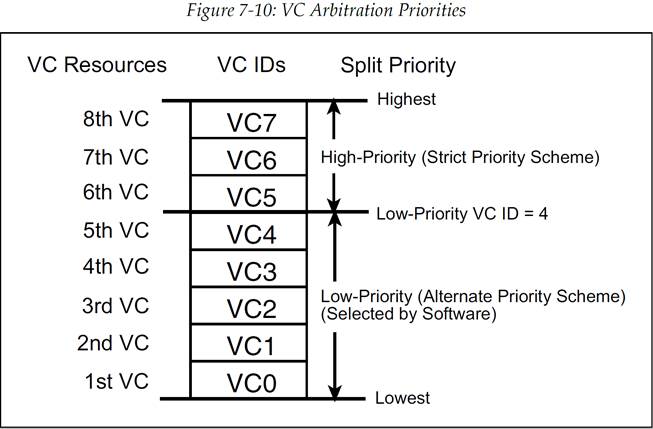
默认的优先级方案是基于 VC ID 的固有优先级(VC0=最低优先级,VC7=最高优先级)。这种机制是自动的,并不需要任何额外配置。图 7-7 展示了一个严格优先级仲裁的例子,它包含了全部 8 个 VC,这其中使用 VC ID 号来管理事务的发送顺序。使用严格优先级仲裁的 VC 的最高编号不能大于扩展 VC 计数(Extended VC Count)字段(如图 7-5)。此外,如果设计者选择让所有的 VC 都使用严格优先级仲裁,那么图 7-8 中的 Port VC Capability Register 1(端口 VC 能力寄存器 1)的 Low Priority Extended VC Count 字段需要固定为 0。
图 7-7:严格优先级仲裁
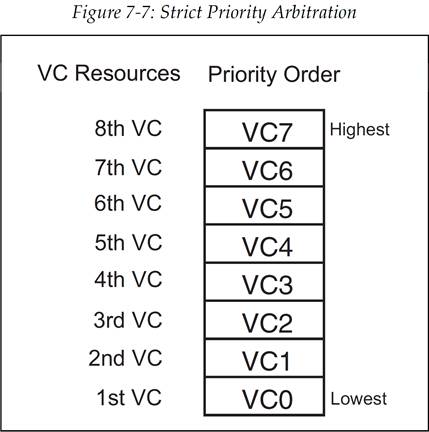
严格优先级方案要求高编号的 VC 永远要优先于低编号的 VC。举例来说,如果全部 8 个 VC 都使用严格优先级方案来管理,那么 VC0 就只能在其他所有 VC 都不需要发送数据包时才能发送数据包。这样的方式可以使得最高优先级的数据包得到很高的带宽以及最低的延迟。但是,严格优先级方案可能会使得低优先级的通道分配不到带宽(一直有高优先级通道占用所有可用带宽),所以必须要小心地确保不会发生这种情况。规范中要求要对高优先级流量进行管理,以免出现低优先级通道的带宽饥饿,并给出了两种对高优先级流量进行管理的方法:
发起事务的端口可以限制高优先级数据包的注入速率,从而就可以为低优先级事务提供更多带宽。
交换机可以在出口端口(egress port)调节多个流量。这种方法可能会限制某些应用和设备的吞吐量,通常这些应用设备是一些试图超过可用带宽限制的高带宽应用和设备。
设备的设计者可能也需要限制使用严格优先级的 VC 的数量,可以通过将 VC 分为 1 个低优先级组和 1 个高优先级组来实现这一目标,在下一小节我们将会讨论这种分组方法。
7.3.3 分组仲裁(Group Arbitration)
图 7-8:展示了端口 VC 能力寄存器 1(Port VC Capability Register 1)的 Low Priority Extended VC Count 字段。这个只读(read-only)字段指定了该设备低优先级仲裁组的 VC ID 上限。例如,如果这个字段的值是 4,那么就说明 VC0-VC4 都属于低优先级组,而剩下的 VC5-VC7 则是高优先级组。注意,若 Low Priority Extended VC Count 的值为 7,则说明没有 VC 使用严格优先级。
图 7-8:低优先级扩展 VC 计数
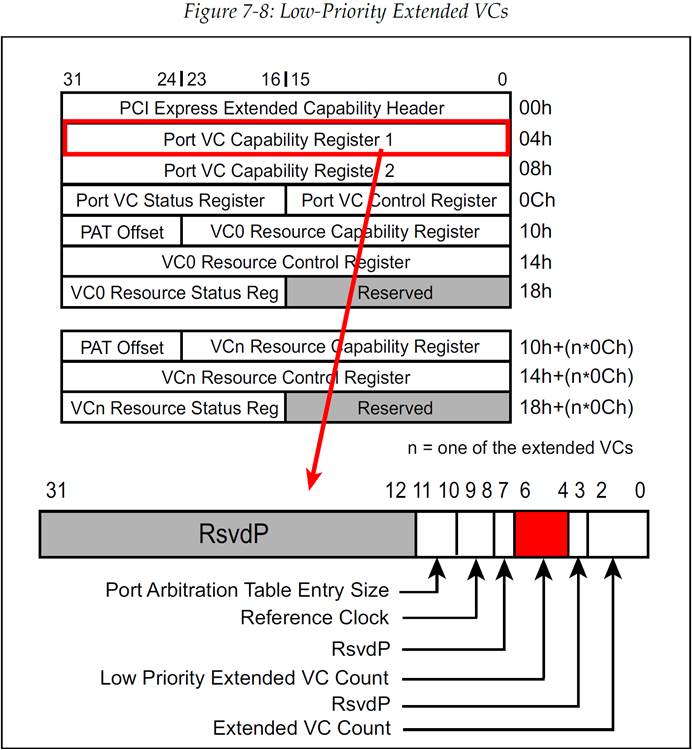
如图 7-10 所展示的那样,高优先级组的 VC 会继续使用严格优先级仲裁,但是低优先级仲裁组则会使用设备支持的其他的一种仲裁方法。如图 7-9 所示,端口 VC 能力寄存器 2(Port VC Capability Register 2)用来表示设备可以支持低优先级组使用哪些替代仲裁方法,而 VC 控制寄存器(VC Control Register)会允许具体选择了哪种仲裁方法。低优先级仲裁方案包括:
基于硬件的固定仲裁(Hardware Based Fixed Arbitration)
加权轮询仲裁 WRR(Weighted Round Robin Arbitration)
图 7-9:VC 仲裁能力字段
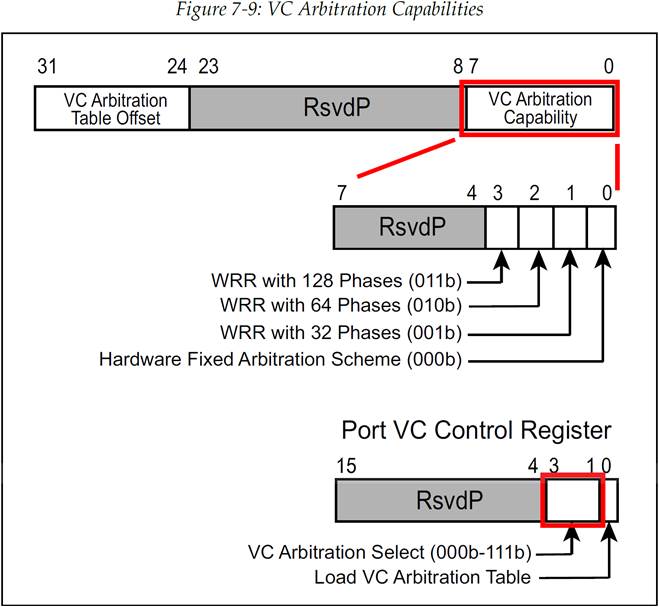
图 7-10:VC 仲裁优先级(分组仲裁)
7.3.3.1 硬件固定仲裁方案(Hardware Fixed Arbitration Scheme)
这个方案定义了一种基于纯硬件的仲裁方法,并且不需要额外的软件设置。这种纯硬件的仲裁方法可以是硬件设计者实现的任何一种方法,而且这种方法还可以基于预期的设备负载或带宽来进行设计。举一个简单的例子,一个普通的轮询调度中,每个 VC 都会得到相同的次数来循环轮流发送数据包。
7.3.3.2 加权轮询仲裁方案(Weighted Round Robin Arbitration, WRR)
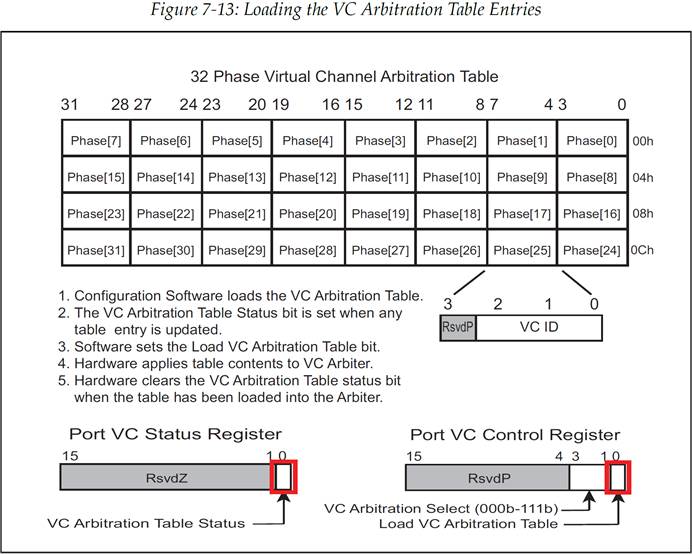
在这种方法中,某些 VC 可以被给予比其他 VC 更大的权重(更高的优先级),这些高权重 VC 会比其他 VC 得到更多的 entries(条目),也就是更多的发送数据包的机会。协议规范定义了三种 WRR 选项,每种选项都具有不同数量的 entries(称为 phase“阶段”)。表项的大小通过往 Port VC Control Register(端口 VC 控制寄存器,图 7-9)中的 VC Arbitration Select(VC 仲裁选择)字段写入相应的值来进行选择。表项中的每个条目都代表一个软件使用低优先级 VC 的阶段。VC 仲裁器会以连续的方式反复的扫描表项的所有条目,然后会通过表项条目内指定的 VC 来发送数据包。一旦一个数据包被发出,那么仲裁器就会马上去扫描下一个条目(entry),也就是进入下一个阶段(phase)。图 7-11 展示了一个拥有 64 个条目的 WRR 仲裁表。
图 7-11:WRR VC 仲裁表

7.3.3.3 建立虚拟通道仲裁表(Virtual Channel Arbitration Table, VAT)
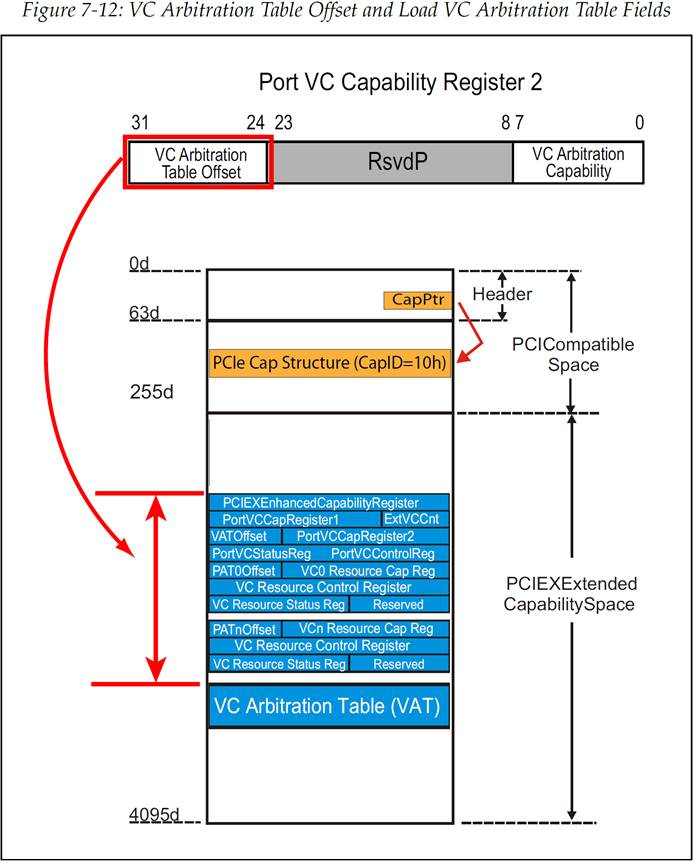
VC Arbitration Table(VAT,VC 仲裁表)位于配置空间中,它的具体的位置的表示方法是一个偏移量,其基址为 VC 能力结构(VC Capability Structure)的地址,如图 7-12 所示。
如图 7-13 所示,VAT(VC Arbitration Table)中的每个条目都是一个 4 bit 字段,它用来指示这个阶段中需要发送数据的 VC 的 ID 号。整个 VAT 表的长度(有多少条目)是通过图 7-9 中的仲裁选项来进行选择的。
图 7-12:VC 仲裁表偏移字段以及加载 VC 仲裁表字段
这个表由配置软件加载,以实现虚拟通道所需要的优先级顺序。当表发生了任何变化时,硬件会设置 VC Arbitration Table Status bit(VC 仲裁表状态位),这为软件提供了一个途径来验证表项虽然发生的改变但是还没有真正作用在硬件上。一旦表被加载完成,软件就会设置端口 VC 控制寄存器(图 7-9)中的 Load VC Arbitration Table bit(加载 VC 仲裁表位)。这会使得硬件对新的表项进行加载,将新的值应用在 VC 仲裁器中。当表项被加载完成并应用后,硬件就会清除 VC Arbitration Table Status bit(VC 仲裁表状态位),这也就通知了软件关于表项加载的操作已经完成。这种表项加载的方式的动机可能是为了在系统运行中也能更改表内容而不中断系统的运行。但是问题是配置写操作一次仅能更新 1 DW 的表内容,它是一种相对慢速的事务,这也就意味着需要一段比较长的时间才能完成整个表内容的更新,而在这段时间里这个表仅仅进行了部分更新。换句话说,这有可能会导致设备在这段时间里继续运行时出现意料之外的行为。为了避免这种情况,这种机制允许软件完成对整个表的更改之后,在统一的一次将它们全部应用在硬件仲裁器中。
图 7-13:加载 VC 仲裁表条目
7.4 端口仲裁(Port Arbitration)
7.4.1 概述(General)
交换机端口和 Root 端口经常接收到一些需要转发至其他端口的数据包。这些数据包虽然由多个端口进行接收,但是它们可能会都需要转发至同一个出口端口的同一个 VC,那么这个时候就需要仲裁机制来决定这些不同端口输入的数据包如何依次的放入同一个目标 VC。类似于 VC 仲裁,端口仲裁也有多种可选方案供配置软件选择。TC、VC 和仲裁方法的多种组合可以支持一系列的服务级别,这些服务级别分为两个大类:
异步类型(Asynchronous):数据包会得到“尽力而为(Best Effort)”的服务,并且可能本身也没有收到任何的偏好需要考虑。许多设备和应用,例如大容量存储设备,对带宽或者延迟并没有很严格的要求,并不需要特殊的定时机制。从另一方面说,通过为不同的数据包建立流量类别(Traffic Class)这种层次结构,那些需求更多的应用所产生的数据包可以仍然划分优先级并且保持其优先级地位。在服务级别需要保证之前,即使是差异化服务也会被认为是异步的。当然,异步服务将总是可用的,而不需要任何特别的软件或者硬件选项。
等时类型(Isochronous):当服务需要保证延迟和带宽时,我们将它移动到等时类型(Isochronous)这一大类中。当两个设备之间通常需要同步连接(synchronous connection)时,这将会非常有用。例如,当耳机直接插入驱动器时,它与从音乐 CD 中获取数据的 CD-ROM 之间使用的是同步连接。然而,当音频数据必须要通过一个像 PCIe 一样的通用总线之后才能到达外部扬声器,那么这个时候的连接就不是同步的了,因为其他的流量也有可能要使用相同的数据流路径。为了达到相同的效果,等时服务必须保证在不阻止其他流量使用链路的同时,能够及时正确的传输这些时间敏感(time-sensitive)的音频数据。毫无疑问,这就必须要有专门的软件和硬件设计来支持它。
关于端口仲裁的概念如图 7-14 所示。需要注意,端口仲裁在系统中的多个位置都会出现:
交换机的出口端口(egress)
支持 Peer-to-Peer 事务时的 RC 端口
某些 RC 出口端口,它们通向的目的地是主存
端口仲裁通常需要对交换机或者 Root 的出口端口的每个虚拟通道进行软件配置。在下面的例子中,Root 端口 2 支持来自 Root 端口 1 和 3 的 Peer-to-Peer 传输,因此这里需要端口仲裁。但是需要注意的是,对于 Root 端口间支持 Peer-to-Peer 的传输是可选的,因此并不是每个 Root 出口端口都需要端口仲裁。
与系统内存相连接的路径是一条有趣的路径。这里可能会有来自多个入口端口(ingress)的数据包在同一时间都想要访问这一个出口端口,因此它需要支持端口仲裁。然而,它所使用的并不是一个 PCIe 端口,因此它并不需要通过配置我们接下来要讨论的 PCIe 寄存器来对端口仲裁进行支持。相反地,RC 需要提供供应商指定的(厂商自定义(vendor-specific))的一组寄存器来提供这方面的功能,它被称为 Root Complex Register Block(RCRB,RC 寄存器块)
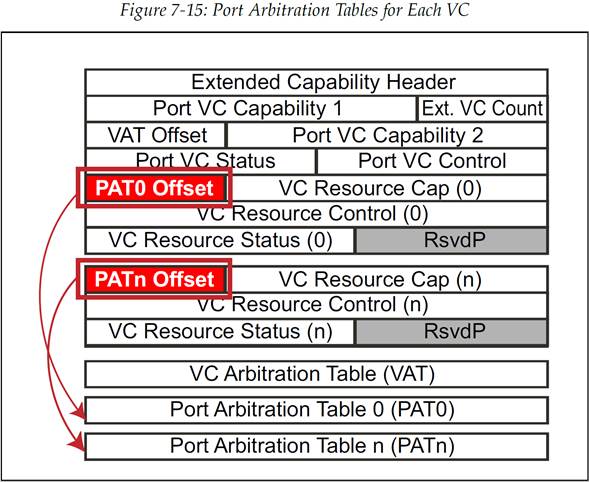
因为出口端口的每个 VC 的端口仲裁都是独立管理的,所以每个支持可编程的端口仲裁的 VC 都需要有一个单独的仲裁表,如图 7-15 所示。只有交换机和 RC 端口才支持端口仲裁表,EP 内是不允许使用端口仲裁表的。
图 7-14:端口仲裁概念
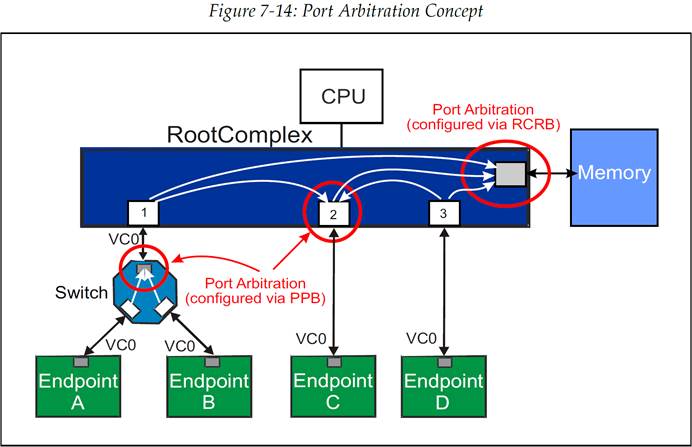
图 7-15:每个 VC 的端口仲裁表
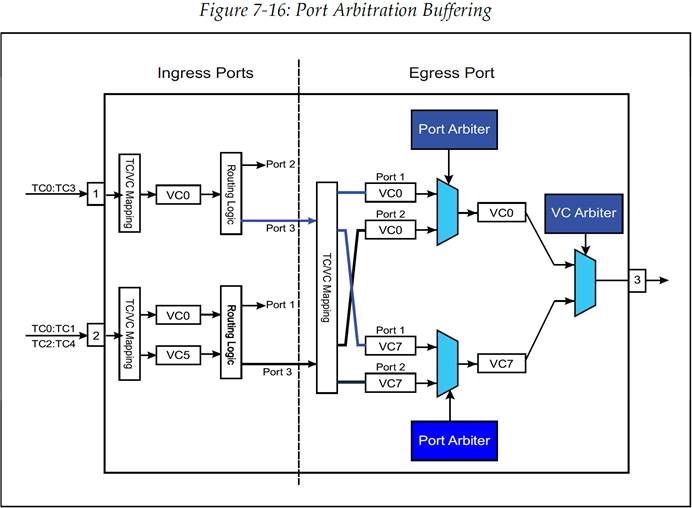
尽管在规范中并没有说明,但是实际上针对不同的数据包流之间的仲裁需要在出口端口中使用额外的缓冲区来积攒来自多个端口的流量,如图 7-16 所示。这个例子中有两个入口端口(端口 1 和 2),它们的事务都被路由至同一个出口端口(端口 3)。交换机所进行的操作包括:
到达入口端口的数据包直接根据 TC/VC 映射被放入相应的流控缓冲区(VC)。
数据包从流控缓冲区中被转发至路由逻辑,路由逻辑将决定数据包被路由至哪个出口端口,并完成路由操作。
被路由至出口端口(端口 3)的数据包通过 TC/VC 映射,以此来确定它们应该被放入出口端口的哪一个 VC。
每个入口端口都存在一组缓冲区与之相关联,允许在端口仲裁完成前都可以追踪入口端口号。
端口仲裁逻辑决定每组入口缓冲区发送事务的顺序。
图 7-16:端口仲裁缓冲
7.4.2 端口仲裁机制(Port Arbitration Mechanisms)
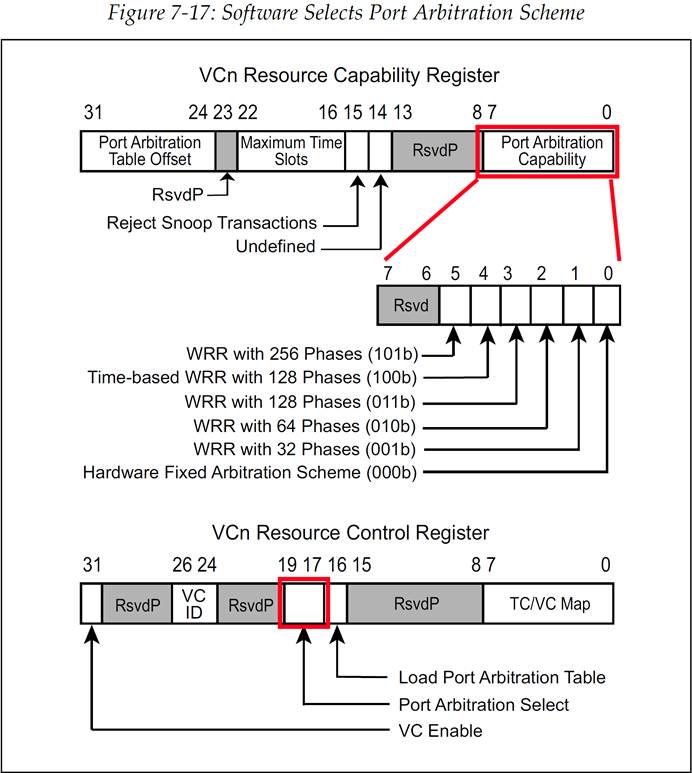
实际上端口仲裁的机制的定义与 VC 仲裁所使用的模型比较相似。配置软件通过读取图 7-17 所示的寄存器来确定端口的能力,并为每个 VC 选择端口仲裁方案。
图 7-17:软件选择端口仲裁方案
7.4.2.1 硬件固定仲裁(Hardware-Fixed Arbitration)
这种仲裁机制不需要软件设置。一旦它被选择使用,那么就仅由硬件来进行管理。实际的仲裁方案由硬件的设计者选择,可能会基于设备的预期需求来进行选择。它也许只是简单的保证了仲裁的公平性,或者是优化了设计的某些方面,但是它无法支持差异化或同步服务。
7.4.2.2 加权轮询仲裁(Weighted Round Robin, WRR)
就像 VC 仲裁中的加权轮询仲裁机制类似,软件可以设置端口仲裁表,以此来让一些端口在仲裁中有更多的被选中的机会。这种方法为来自不同端口的流量分配了不同的仲裁权重。
在扫描仲裁表时,其中的每个阶段(Phase)都会指定下一个被接收的数据包的入口端口号。一旦当前阶段的数据包被发送,仲裁逻辑就会立即跳转至下一个阶段。如果并没有数据包需要发送给被选中的端口,仲裁器就将会立即推进到下一个阶段去。对于仲裁表中的这些条目并没有与它们相关的时间值。
对于 WRR 端口仲裁,有四种仲裁表长度可以使用,仲裁表长度确定了它包含的阶段数量。若仲裁表中的条目数量越多,那么也就可以使用更复杂更特别的仲裁选择比率。而从另一方面来说,仲裁表条目数量越少则会使用更少的存储空间以及更低的成本。
7.4.2.3 基于时间的加权轮询仲裁(Time-Based WRR Arbitration, TBWRR)
要对等时类型的服务进行支持,这种机制是必需的。像它名字所述的那样,基于时间的加权轮询(TBWRR)为每个仲裁阶段都加入了时间元素。就像在 WRR 中,端口仲裁器从仲裁表中获得当前阶段所指示的端口号,然后根据这个端口号去从相应的入口端口 VC 缓冲区中取出数据包用于传输。而对于现在的 TBWRR 来说,基于时间的仲裁器并不会立即推进到下一个阶段,而是要等到当前的虚拟时隙(timeslot)过去之后才推进到下一个阶段。这确保了从入口端口接收事务的时间间隔是确定的。如果被选中的端口并没有需要发送的事务,那么也会等待至下一个时隙,而在这中间的这段等待时间不会有任何信息被发送。注意,时隙的并不控制整个传输所持续的时间,而是控制两次传输之间的间隔。这里的事务传输的最大持续时间是完成轮询并且返回到初始时隙中所花费的时间。时隙的长度也许在未来会发生变化,但是目前它的值为 100 ns。
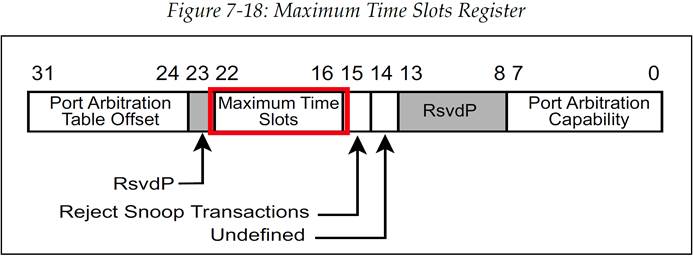
基于时间的 WRR 仲裁所支持的最大长度的仲裁表包含 128 个阶段,但是一个具体的 VC 可用的仲裁表条目实际数量可能会低于这个数值。这个值是由硬件初始化,并通过每个支持 TBWRR 的 VC 的 Maximum Time Slots 字段来进行表示,这个字段如图 7-18 所示。
图 7-18:最大时隙寄存器
7.4.3 加载端口仲裁表(Loading the Port Arbitration Tables)
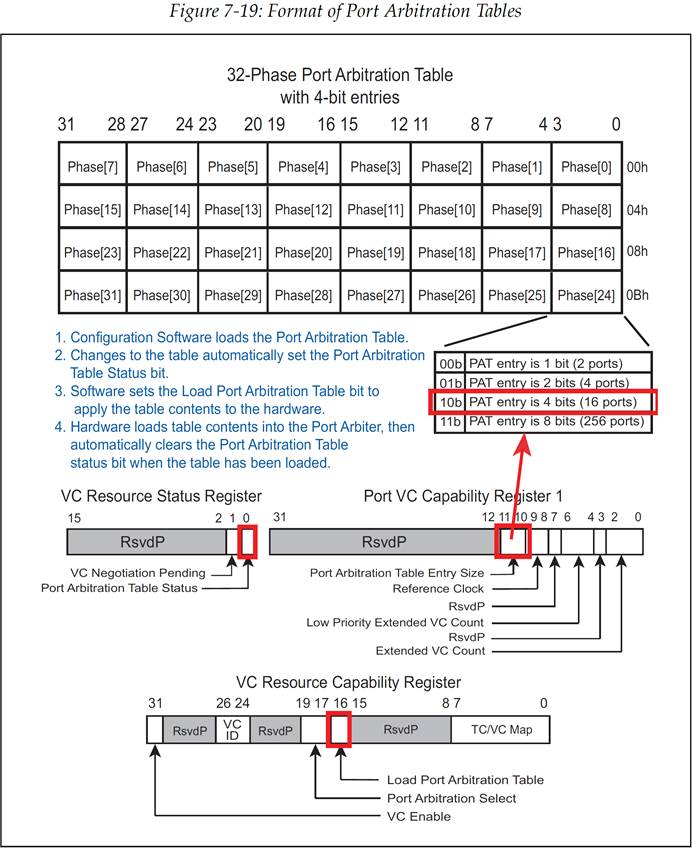
端口仲裁表的实际大小和格式,是一个和阶段数量和入口端口数量有关的函数,这里的入口端口可以是交换机端口、根复合体寄存器块(Root Complex Register Block, RCRB)或者是支持 Peer-to-Peer 传输的 RC 端口。端口仲裁表所支持的最大入口端口数量为 256 个。实际的仲裁表中每个条目的 bit 数量,其设计考虑和管理都依赖于可以将事务传输至此出口端口的入口端口数量。每个仲裁表条目的大小表示在端口 VC 能力寄存器 1(Port VC Capability Register 1)中的 Port Arbitration Table Entry Size(端口仲裁表条目大小)字段,这个字段的长度为 2 bit。其中各个数值含义为:
00b:1bit(也就是在两个端口之间进行选择)
01b:2 bits(4 个端口)
10b:4 bits(16 个端口)
11b:8 bits(256 个端口)
配置软件通过将各端口号填入仲裁表来完成仲裁表的加载,以实现支持的每个 VC 所需的端口优先级功能。如图 7-19 所示,仲裁表的格式取决于每个条目的实际大小以及该设计中所支持的阶段的数量。
图 7-19:端口仲裁表格式
7.4.4 交换机 仲裁示例(交换机 Arbitration Example)
现在让我们考虑一个 3 端口交换机的例子,以此来对端口仲裁和 VC 仲裁进行举例讲解。我们在示例中假设,由入口端口 0 和入口端口 1 接收的数据包会向上行移动,而端口 2 则是面向上行的出口端口(也就是面向 RC)。下面的关于这个示例的讨论可以参照图 7-20。
图 7-20:交换机中的仲裁示例
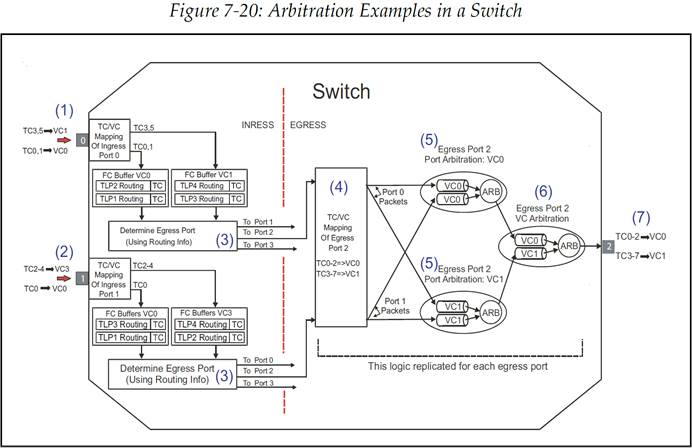
到达入口端口 0 的数据包根据 TC/VC 映射关系,被端口 0 放入相应的接收 VC 中。如图中展示的一样,流量类别为 TC0 或是 TC1 的 TLP 会被放入端口 0 的 VC0 缓冲区;流量类别为 TC3 或是 TC5 的 TLP 会被放入端口 0 的 VC1 缓冲区。在这个端口的链路上,其他的 TC 都是不允许出现的,如果出现了一个数据包而它的 TC 无法正确的映射到任何一个存在的 VC,那么就会被视作发生了一个错误。
到达入口端口 1 的数据包也会根据 TC/VC 映射关系被放入相应的 VC 中,但是端口 1 的 TC/VC 映射关系和端口 0 的不同。在端口 1 中,流量类别为 TC0 的 TLP 会被放入端口 1 的 VC0 缓冲区;流量类别为 TC2-TC4(TC2、TC3、TC4)的 TLP 会被放入端口 1 的 VC3 缓冲区。链路上不允许出现其他 TC 的数据包。
对于端口 0 和端口 1 这两个端口来说,它们接收的数据包的目的出口端口是由每个数据包的路由信息来决定的。例如,Memory 或 I/O 请求 TLP 会使用地址路由方式。
所有目的出口端口为端口 2 的数据包,都会被呈交给端口 2 的 TC/VC 映射逻辑。如图中所示的那样,流量类别为 TC0-TC2(TC0、TC1、TC2)的 TLP 会被放入端口 2 中被标识有 TLP 各自入口端口号的 VC0 缓冲区;流量类别为 TC3-TC7(TC3、TC4、TC5、TC6、TC7)的 TLP 会被放入端口 2 中被标识有 TLP 各自入口端口号的 VC1 缓冲区。
端口仲裁是端口 2 中的每个 VC 独立进行的,各个 VC 会将自己的一组带有各入口端口号标识的缓冲区中的数据包进行排队,以此来决定哪个入口端口传来的 TLP 将要成为下一个真正被放入真实 VC 的数据包。
最后,由 VC 仲裁来确定在各真实的 VC 缓冲区实际在链路上传输事务的顺序是怎样的。
注意,VC 仲裁仅会在有足够的流控 Credit 时,才会去选择数据包用于传输。
7.5 多功能端点中的仲裁(Arbitration in Multi-Function Endpoints)
有一组寄存器称为 Multi-Function Virtual Channel(MFVC)Capability(多功能虚拟通道能力寄存器组),这组寄存器是为了在具有多种 Function 的 EP 设备中实现 QoS 的这种特定情况而定义的。
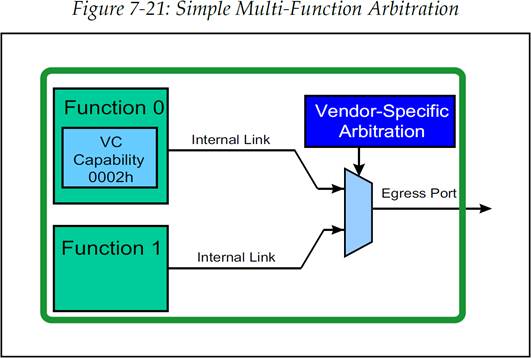
在规范中描述了这种仲裁的两种情况。第一种情况,如图 7-21 所示,EP 中虽然有两个 Function,但是只有 Function 0 中包含 VC 能力寄存器(VC Capability Registers),并且所有的 Function 的任务分配都是相同的。对于这种情况,Function 之间的仲裁方式将按照一些厂商指定(厂商自定义(Vendor-Specific))的方法去进行。这是最简单的方法,但是这无法在内部包含一个标准结构用于定义不同 Function 的请求的优先级,因此它无法支持 QoS。
图 7-21:简单的多 Function 仲裁
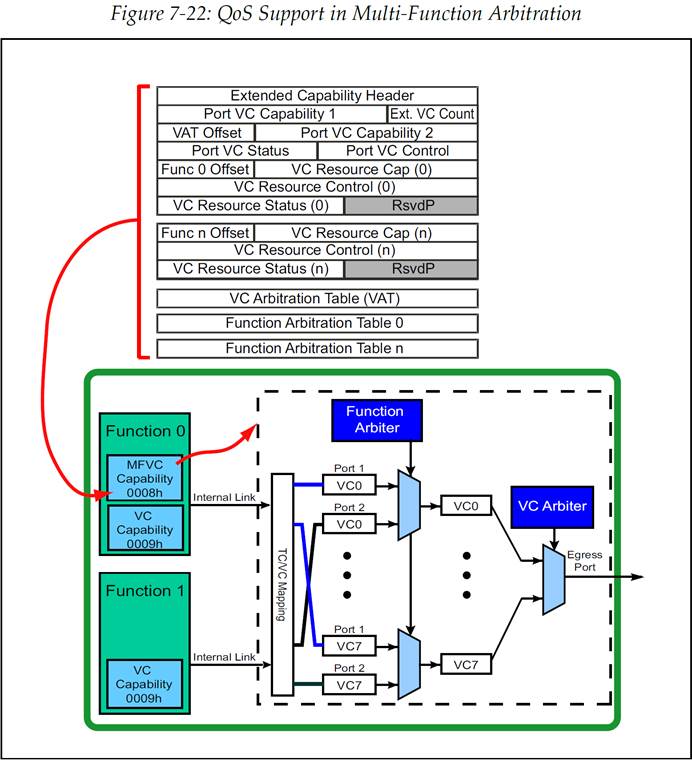
如果希望支持 QoS,那么就需要在 VC0 中实现一个 MFVC(Multi-Function Virtual Channel)寄存器组,并且每个 Function 都要有自己独立的一组 VC 能力寄存器。为了保持软件的向后兼容性,规范中声明,所有不使用 MFVC 的设备的 VC Capability ID(VC 能力 ID)都必须为 0002h,而所有内部实现了 MFVC 的设备的 VC Capability ID 都必须为 0009h。
图 7-22:展示了 MFVC 寄存器组,以及一个示例框图,示例中的 EP 内包含两个 Function,这个 EP 的端口支持 2 个 VC。每个 Function 都有自己的事务层以及 VC 能力寄存器组,但是并没有实现更低的层级。相反地,它们都连接到了二者共享的端口的事务层,这个共享端口具有所有的层级。这种共享硬件接口的方式可以降低成本和开销,并且各 Function 事务层中添加的 MFVC 寄存器组使得 Function 可以处理等时流量(Isochronous Traffic)。
在图 7-22 中可以看到,MFVC 寄存器仅存在于 Function 0 中,并定义了此接口使用的 VC 以及仲裁方法。MFVC 寄存器组看起来与 VC 能力寄存器组十分相似,它可以支持 VC 仲裁与 Function 仲裁。由于来自多个不同 Function 的数据包有可能在同时访问同一个 VC,因此就需要 Function 仲裁来决定不同 Function 数据包之间的优先级。这种方式在现在看来应该是非常熟悉的,因为它与此前的端口仲裁其实是相同的概念,甚至连仲裁方法选项都是一样的,包括 TBWRR。VC 仲裁选项也与单 Function VC 寄存器中的仲裁选项相同。
图 7-22:多 Function 仲裁中的 QoS 支持
7.6 等时服务支持(Isochronous Support)
前面的内容中提到,并不是每个设备或者应用都需要支持等时服务,但是也有一些是必须要支持同步服务的。由于 PCIe 从设计之初就希望支持等时服务,因此让我们来考虑一下要支持它的话会有什么样的要求。
7.6.1 时间规划就是一切(Timing is Everything)
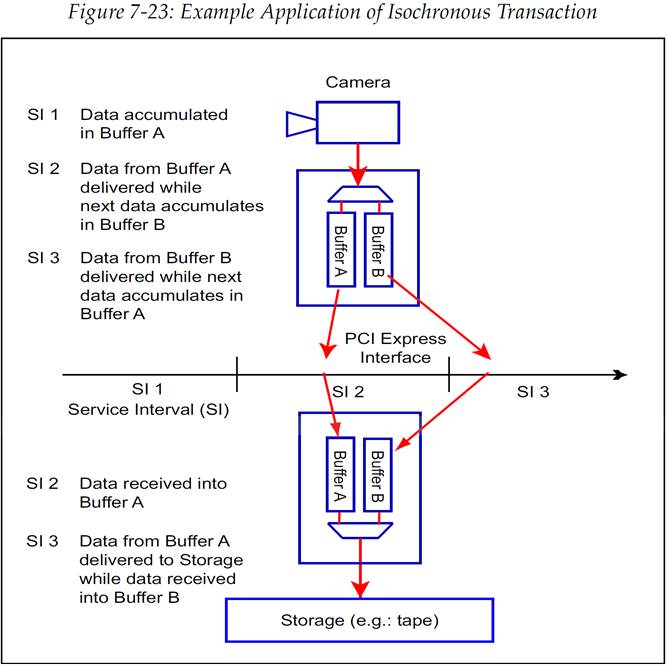
考虑图 7-23 中展示的例子,例子中的同步连接(synchronous connection)是我们所期望的,但是这是无法实际实现的。相反地,我们通过等时机制来模拟一个同步连接。在这个例子中,等时性(Isochrony)定义了在服务间隔内需要被传输的用来完成服务需求的数据量。下面对操作流程进行了描述:
同步源(摄像机和 PCIe 接口)在第一个等时服务间隔(Service Interval,SI 1)中在缓冲区 A 积累数据。
摄像机在下一个服务间隔(SI 2)中通过通用总线发送完缓冲区 A 中所有被缓存积累的数据,同时也将下一块新数据积累在缓冲区 B 中。
明显地,系统必须要能保证缓冲区 A 中的全部内容要在这个服务间隔内发送,不管链路上是否还有其他流量在传输。要做到这一点,可以给这些时间敏感(time-sensitive)数据包分配高优先级,并且按照需要规划仲裁方案使得这些数据包即使在有其他流量竞争的情况下也能被优先处理。还需要注意,只要所有的数据在时间窗口内发送出去即可,而至于它们具体什么时间到达在这里并不关心,它们可能会在服务间隔中很分散的发送,也有可能集中在服务间隔的某一时刻紧密的发送。只要它们都在服务间隔中被发送出去,那么就依然可以做到需要的保证。
- 在 SI 2 中,录音机接收到数据,并将这些输入数据缓存起来,随后这些数据可以在 SI 3 被传递到存储介质来完成录制。摄像机也会在 SI 3 期间将缓冲区 B 中的数据卸到链路上,同时也在 SI 3 内在缓冲区 A 中积累新的数据,以此循环进行。
图 7-23:同步事务的示例应用
7.6.1.1 如何定义时间规划(How Timing Is Defined)
PCIe 使用 TBWRR 端口仲裁机制中的时隙(time slot)来定义等时时长。目前,每个时隙是 100 ns,它代表 TBWRR 仲裁表的 128 个条目中的 1 个。一旦设置完成,仲裁器就会每 12.8 μs 循环重复一次这个仲裁表,这也代表全部的服务间隔。
要想让一个等时路径像预期的一样工作,这需要有一定的考虑。首先,数据包必须在可预测的时间点、以固定的间隔被发送。第二,等时数据需要被传输的最大数据量必须是要提前可以获知的,并且数据包不允许超过这个最大值上限。第三,链路必须要有足够的带宽来支持一个给定时隙内所要传输的数据量。
考虑接下来这个例子。一个单通道链路工作在 2.5 Gbps,每 4ns 发送一个符号(10bit 符号)。也就是说每个 100 ns 的时隙可以发送 25 个符号,但是这足够吗?在很多情况下这是不够的,因为 1 个 TLP 需要 28byte 组成 头部、序列号(Sequence Number)、LCRC 等等的常规开销。这意味着 100 ns 根本不足以完成这些常规开销的发送,更不用说发送数据负载了。如果我们需要发送 128byte 的数据,那么需要的带宽就将是 128 Byte + 常规开销 = 156 Byte。解决这个问题的一个选项是将链路宽度增加至 8 通道,这使得一次可以传输的数据量变为原来的 8 倍。这种改变会使链路在 100 ns 内可以传输 200 Byte,那么也就可以在 1 个时隙中发送所有的等时数据。另一种解决方法是依然使用单通道链路,但是可以给予端口更多的时隙用于发送数据,比如将服务间隔由 1 个时隙增加到 8 个时隙,那么就也可以在 1 个服务间隔中传输 200 Byte 数据了。具体的选择哪种解决方法取决于成本和性能的权衡,但是系统的设计者必须知道等时路径对时间规划和带宽的要求,这样才能正确的建立等时路径。
7.6.1.2 如何实施时间规划(How Timing Is Enforced)
像前面的例子中所描述的,为了要使一个设计进行正确的操作,时间规划已经成了必不可少的一部分,它是由到目前为止我们所讨论的多种元素的组合来完成执行的。首先,软件中必须选择高优先级 TC,在硬件中配置 VC,并定义 TC 到 VC 的映射关系,以此来让正确的数据包放入高优先级 VC 中。然后,期望的的时间规划其实是一个仲裁方案规划问题,通过这个规划来适配特定时间内所需要的带宽。例如,VC 仲裁可能会使用严格优先级仲裁,因为这是唯一可以确保高优先级数据包不会被其他数据包阻塞延迟的仲裁方式。而对于端口仲裁则必须是 TBWRR,这样才能执行确定好的时间规划。
7.6.2 软件支持(Software Support)
要支持等时服务,还需要系统中各个软件元素之间的协调合作。在一个 PC 系统中,设备驱动会向 OS(操作系统)报告等时服务的需求和能力(Capabilities),OS 会根据这些信息对整个系统的需求进行评估,并为系统分配合适的资源。嵌入式系统会有所不同,因为所有的这些各部分的信息在一开始就是已知的,所以这里的软件可以更简单一些。在接下来的讨论中,我们将会描述 PC 系统中的情况,因为嵌入式系统的情况只是 PC 情况中更简单的一个子集。
7.6.2.1 设备驱动程序(Device Drivers)
一个设备驱动必须能够将时间规划的需求报告给用于监督等时操作的软件,并在真正尝试发送等时服务数据包之前,先要获得这个软件的许可。需要注意的重要的一点是,驱动级软件不应该自己直接改变硬件配置或者是仲裁策略,即使它有这个能力也不行,因为这将会引起混乱。如果多个驱动程序都各自独立的尝试更改硬件配置或仲裁策略,那么最后进行更改操作的驱动程序将会把之前的更改都覆盖掉。为了避免这种情况,一种被称为等时代理(Isochronous Broker)的 OS 级程序将会接收来自系统设备的时间规划请求,并以一种协调的方式来分配系统资源,以此来适配所有的这些请求。
7.6.2.2 等时代理(Isochronous Broker)
这种程序用来管理端到端的等时数据包流。它从设备驱动接收到等时时间规划请求,用一种能适配目标路径上的各个请求的方式,来协调分配系统资源。在规范中,这被称为“在一对 Requester/ 完成方(Completer)(请求者/完成者)和 PCIe 结构之间,建立了一个等时契约(Isochronous Contract)”。要做到这些,需要确定期望的路径上确实可以支持等时流量,然后就编程写入合适的仲裁方案,以确保它在指定的时间规划要求下工作。
7.6.3 将各部分结合起来(Bringing It All Together)
到目前为止,我们应该已经相当清楚需要做些什么来支持系统中的等时流量,但是让我们来看最后一个例子,在这个例子里将会把之前的各个内容部分全都结合起来。如果我们继续对此前的视频捕捉示例进行展开详述,以此来展示一个更加复杂的系统,如图 7-24 所示的系统,当摄像机可以把捕捉到的视频数据传送至系统存储时,我们就可以基于它来讨论这个系统中所必需的每个部分。这对于等时服务来说是一个比较困难的系统环境,因为系统中存在许多需要竞争路径上的带宽的设备,但是这也使得这个例子非常适合用来讲解这些过程中需要考虑的方方面面。
7.6.3.1 端点(Endpoints)
让我们从系统的最底部开始,对于录像 EP 设备本身,它的 PCIe 接口中需要有什么?在硬件中,如果我们想要区别不同的数据包,那么就需要 1 个以上的 VC。为了简化例子,我们假设这个设备是一个单 Function 设备。设备驱动程序需要向 OS 级的等时代理程序报告设备的能力(Capabilities)和等时时间规划需求,等时代理程序将会根据这些信息对系统进行评估,并向设备驱动报告是否可能建立等时契约以及软件应该使用哪些 TC。
驱动程序则将会将对 VC 的编号和数量进行编程写入,并将相应的 TC 映射至各 VC。它也很有可能会将高优先级通道的 VC 仲裁编程为严格优先级仲裁(Strict Priority)。这里需要注意的一点是,仲裁必须要是“公平的”,意思是那些低优先级通道不能出现发生饥饿(starvation)。这意味着那些高优先级 VC 不能一直占用仲裁让自己的流量处于待发送状态,而是要随时间分批的传输数据包。
在结束对 EP 的讨论之前,还需要注意关于链路操作的另一个问题,那就是流量控制。设备在等时路径上的接收缓冲区必须要足够大,只要数据包是按照等时契约(Isochronous Contract)均匀的输入,那么这个缓冲区就要大到在不需要任何反压(backpressure)的情况下能够处理预期的输入数据包流。此外,流控更新 DLLP(Flow Control Update)的返回速度必须足够快,以此来避免传输停滞。
图 7-24:等时系统示例
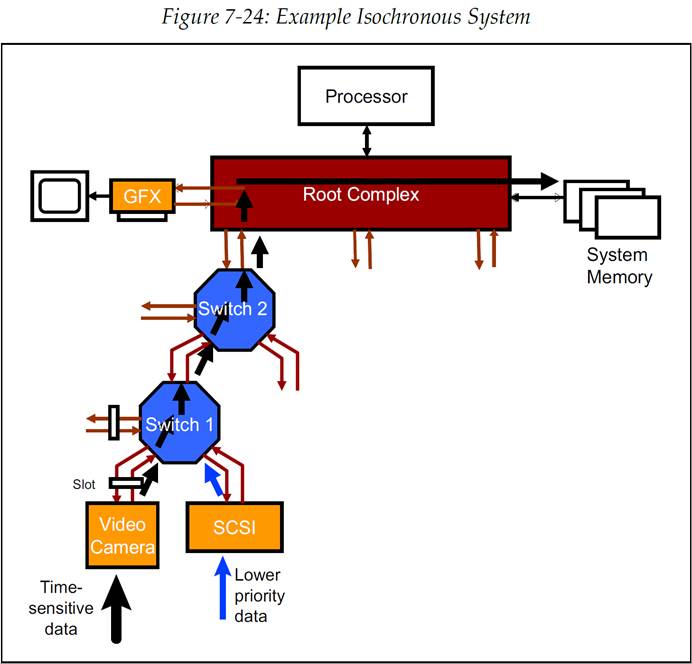
7.6.3.2 交换机(交换机(交换机 es))
在讨论了 EP 之后,接下来让我们考虑一下在 EP 与 RC 之间的交换机中需要提供什么。交换机通常是没有自己的设备驱动程序的,所以只能由 OS 级软件(如等时代理 Isochronous Broker)来读取它们的配置信息,以此来确定这些交换机能支持怎样的服务。首先,在等时路径上的所有端口都必须要支持至少 2 个 VC,且链路两端的 TC/VC 映射关系也必须是相匹配的。要记住,一旦数据包到达了交换机端口的事务层,那么数据包中只有 TC 信息而没有 VC 信息,TC 具体对应哪个 VC 是每个端口自己指定的而不会将这个信息携带在 TLP 中。交换机 1 的下行端口与它下方连接的 EP 的各自 TC/VC 映射关系必须要相匹配,但是至于其他的交换机端口可以是不同的以此来匹配它们各自链路上的 EP。
仲裁问题(Arbitration Issues)
仲裁方法的选择是很直接的。为了简单起见,在我们的例子中的等时路径上承载的流量是单向的。对于在存储器读取操作中,其实是有可能出现双向的等时流量的,但是在我们的例子中选取的是类似视频流的情况。
等时出口端口使用的 VC 仲裁通常是严格优先级方案,原因与 EP 相同。端口仲裁则将会使用 TBWRR 方案,这意味着软件必须了解适当的访问比率,并将端口仲裁表(Port Arbitration Table)编程写入,以此来实现这种端口的访问比率。如果路径中有多个交换机,那么要做到这一系列事情可能并不是听起来的那么简单,因为即使他们使用的都是相同的 TBWRR 仲裁方案,也无法很清晰的知道它们各自的服务间隔(service interval,SI)是如何协同工作的。如果几个交换机的 SI 之间并未对齐,那么就意味着等时的时间规划更加难以实现,这将取决于链路的繁忙程度。但是规范中并没有考虑 SI 之间的协调合作,因此这里就将再次涉及到一个非标准方法。显然,如果在一个等时路径上并不存在多个交换机而只有 1 个,那么这个问题就将会被大大简化。
时间规划问题(Timing Issues)
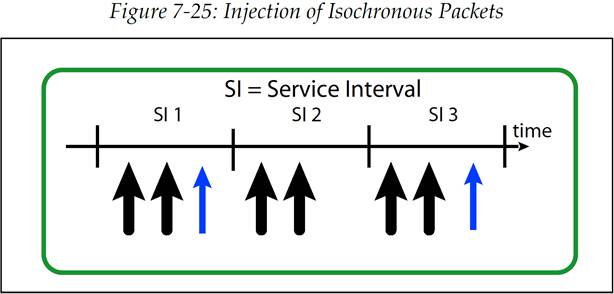
图 7-25:展示了我们的例子中数据包在两个 EP 间传送的时间点。粗线条的大箭头是来自视频设备的数据包,它具有已知确定的大小,并按照周期性的、确定性间隔的进行发送。细线条的小箭头则是代表来自 SCSI 驱动器的数据包,它具有较低的优先级且发送时间点是不可预知的。在 EP 中,数据包只需要简单的包含 TC 即可,但是交换机还需要确认执行了合适的时间规划方案。这是通过使用 TBWRR 来完成的,它将会指定在一个给定的时间点上,哪个端口可以进行访问,以及访问时间有多长。由于知道等时数据包的大小以及传送频率,这使得软件可以正确的安排时间规划,但是什么样的时间规划才是我们需要的呢?
图 7-25:等时数据包的注入
首先,让我们通过一个简单的示例来回顾一下需要涉及到的参数。回忆一下,PCIe 中基于参考时钟周期定义了时隙(time slot),而时隙的长度是由端口能力寄存器 1(Port Capability Register 1)中的参考时钟字段(Reference Clock)所给定的。目前,这个字段的值只能是 100 ns,并且 TBWRR 仲裁表只能是 128 个条目的大小。服务间隔(Service Interval,SI)的长度就是它们的乘积,也就是 12.8 μs。一个给定设备的带宽可以用下面给出的公式来表达,其中 Y 表示 1 个时隙中将要发送的数据量(规范中声明,必须要将配置过程中编程写入的 Max Payload Size 值用于这个带宽的计算中,也就是先假设 1 个时隙就能传输 1 个数据包),M 表示的是时隙的数量,T 表示整个 SI 长度。举例来说,如果我们选择 Payload 为 128 Byte,又已知 SI 为 12.8 μs,那么对于分配的每个时隙来说,BW=10 MB/s。
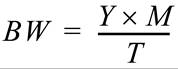
现在让我们考虑一个更贴近实际的例子。假设链路工作在 Gen2 的速率,视频设备需要保证有 100 MB/s 的带宽,且它将会发送数据负载为 512 Byte 的数据包,我们先假设 1 个时隙就能发送 1 个数据包,代入公式中得到 M=2.5,也就是在这种情况下要在 1 个 SI 中发送 2.5 个 512 Byte 数据包。
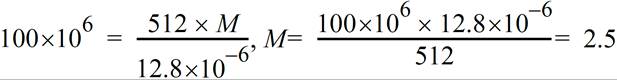
但是实际上 1 个时隙中可以传输多少数据呢?这个问题的答案当然与链路速率以及链路宽度有关。在 5.0 Gb/s 的速率下,每发送 1 个 10bit 符号就需要 2ns,因此在每个通道中 100 ns 则可以传输 50 个符号。如果数据包的大小是 512 Byte 再加上 28Byte 左右的 头部,那么使用 x1 链路传输大小为 550 个符号的数据包则需要 11 个时隙。在有需要的时候,可以让同一个端口得到连续的多个时隙,这是一种解决办法。由于将要发送的数据包的大小是确定一致的,我们不能真的就将 M 定为 2.5 个 512 Byte,而是应该将其定为 3。对于我们的公式来说,在 1 个 SI 中发送 3 个 512 Byte 的带宽实际上是 120 MB/s。这虽然高于我们的需求带宽,但是确实解决了我们的问题。由于刚才计算过传输 550 个符号需要 11 个时隙,那么传输 3 个就需要 11 × 3 = 33 个时隙,在 1 个 SI 中还留有 95 个时隙用作它用。在 1 个 SI 中的 3 个时隙组(每组 11 个)中,每一组内的 11 个时隙必须是连续相邻的,但是组与组之间可以是分开的。
另外一个解决办法就是增加链路宽度。尽管这样的解决办法会增加硬件开销,但是如果使用 11 通道的链路则可以真正的在 1 个时隙内完成需要的数据的发送但是在 CEM 规范中(PCIe Card Electromechanical Specification(CEM 规范)),并没有 x11 选项,但是可以使用其中的 x12 选项来应用在我们的例子中。使用更宽的链路意味着软件只需要为每个数据包分配 1 个时隙,因此只需要在 1 个 SI 中分配 3 个时隙,即可满足本例子中设备的等时流量带宽需求。与 x1 的情况不同,现在我们不需要让分配的时隙连续相邻。相反地,它们可以以某种更优的方式分散在 SI 中。
带宽分配问题(Bandwidth Allocation Problems)
对于等时流量来说,必须要设计好 TBWRR 仲裁表来保证有足够的及时的带宽,并且这部分带宽不会被其他流量所影响。如图 7-25 中所示,SCSI 控制器在 SI 1 中发送了 1 个数据包,在 SI 3 中发送了另一个数据包。如果时间规划就按照这样,允许 EP 每个 SI 发送 1 个数据包,那么这样的方式是可行的。
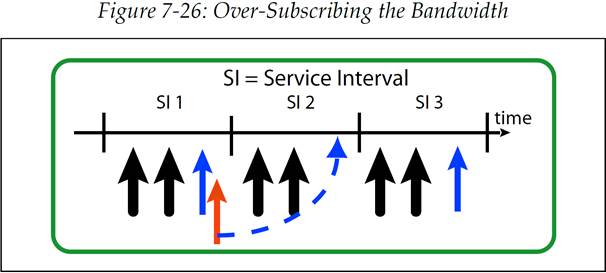
现在我们假设 SCSI 控制器尝试发送更多的数据包,其数量已经超过了 SI 1 对它的许可数量,如图 7-26 所示。这是规范中提到的两个带宽分配问题中的第一个,它被称为“过载(oversubscription)”。这将会影响到等时流量,但是这个问题可以通过合理的规划 TBWRR 仲裁表就能比较容易的避免,因为在某个特定的时间点下,只有被仲裁选中的端口可以发送数据包。如果这个端口在发送完仲裁许可的数据包后依然有很多数据包在队列中等待发送,那么它也需要等到下一次被仲裁选中才能继续发送后续的部分数据包,对于这个例子中也就是 SCSI 控制器想在 SI 1 中多发送的那一个数据包实际上可能会放到 SI 2 中去发送。最终,这种“过载”会导致发送处的流控反压(backpressure)。
图 7-26:超额使用带宽
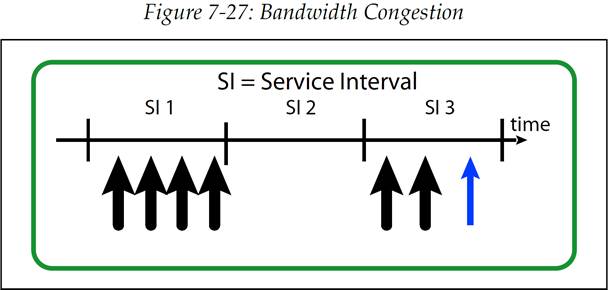
第二个问题被称为“拥塞(congestion)”,当在一个给定的时间窗口内存在了太多等时服务请求时,就有可能会发生这种问题,如图 7-27 所示。这个问题和第一个有点相似,但是它是无法那么简单就解决的。与之前的情况不同,这里不能将高优先级数据包推迟到下一个时隙发送,因此系统必须要有办法来处理全部的这些请求。要纠正拥塞的问题,软件需要改变发送数据包时间点的分布,以便它们都能够得到可用硬件带宽的支持。
图 7-27:带宽拥塞
延迟问题(Latency Issues)
管理数据包发送的延迟也是等时性很重要的一部分,这个延迟包括网络结构传播延迟与完成方(Completer) 延迟。网络结构传播延迟取决于系统中各种组件之间的链路的全部特性,特别是链路宽度和操作频率。一种将这个网络结构传播延迟值最小化的简单方法,就是对 PCIe 拓扑结构的等时路径上的复杂度进行约束。完成方(Completer) 延迟取决于目的 EP 内部特性,例如存储速率以及内部仲裁方式等等。
7.6.3.3 根复合体(Root Complex)
RC 的仲裁和时间规划需求和交换机是一样的。它会从多个下行端口接收数据包,并通过符合前面所描述的等时性规则的方法将它们转发至目的地。然而,这些事情的完成方法大都是 Vendor 特定的,因为规范中并没有定义等时服务的 RC 工作方式或者是它应该如何被编程。
问题:窥探(Problem: Snooping)
在影响 RC 的时间规划和延迟的各种因素里,我们还有一个没有进行讨论,那就是窥探过程(process of snooping)。一般情况下,对系统内存的访问会发生在处理器认为可缓存(cacheable)的位置,这意味着这个位置的内存可以在它的本地缓存中保存一个自己的临时副本。如果外部设备尝试访问这个内存区域,那么芯片组必须先检查处理器缓存,然后才能允许此次内存访问,因为缓存中缓存的副本可能已经被更改过,与原内存区域中的数据已经不相同了。如果缓存中缓存的副本确实被更改过,那么在设备访问这个内存区域之前,先要让缓存中的数据写回内存(写回(Write Back))。虽然对内存缓存一致性的确认工作是有必要的,但是问题就是这个窥探过程是需要花费时间的。它需要花费的时间通常是在一个范围内有限的,但是是不可预测的,因为它取决于 CPU 在当时具体正在执行什么工作。结合上时间规划的时间确定性需求,窥探时间的不确定性很有可能会破坏等时数据流。
窥探问题解决方法(Snooping Solution)
对于外部设备来说,一种避免窥探的方法就是仅访问不可缓存(Uncacheable)的内存区域。另一种方法是由软件设置高优先级数据包头部中的“No Snoop(无窥探)”属性位。这种方式将会强制芯片组跳过窥探步骤,不管内存是否是不可缓存(uncacheable)都直接去访问内存,这需要软件用一些方法来保证这样做不会引发问题。为了将这种方式作为等时路径的一个需求来执行,对于高优先级 VC 来说,硬件可以对 RC 端口中的另一个 bit 进行初始化配置,它叫做“拒绝窥探事务(Reject Snoop Transaction)”,如图 7-17 中所示的 VC 资源能力寄存器。这样做的目的是,让这个 VC 只允许传输 No Snoop 的事务。任何输入的没有设置 No Snoop 属性位的数据包都将被丢弃,以此来确保时间规划的时间确定性不会被窥探过程花费的不确定时间所破坏。
7.6.3.4 电源管理(Power Management)
电源管理是一个简单的监测过程,但是当 PCIe 中的一段路径是时间敏感路径的时候,那么这个路径上设备的电源管理机制 PM(Power Management)就需要仔细的处理。配置软件可以读取到每种 PM 条件下造成的延迟,并从中选择一种 PM 条件使得它的延迟可以满足时间规划要求。最简单的办法就是在等时路径上禁用 PM。设备可以进入设备状态 D0 然后就停留在这个状态,同时禁用硬件控制的链路电源管理机制(更多关于 PM 的内容请参阅 Chapter 16“Power Management”)。
7.6.3.5 错误处理(Error Handling)
最后,还剩下最后一个问题:当链路上出现错误时应该怎么办。ACK/NAK 协议提供了一个自动地、基于硬件的重试机制(Retry)来纠正出现传输问题的数据包。这个原本还不错的特性会给等时性带来一个问题,因为它需要花费时间来完成,并且它用来解决几个传输错误花费的时间也会有较大差异,这取决于具体检测到了什么样的错误。
要解决这个问题,我们需要知道系统能容忍多少不确定的时间,使得系统仍能提供等时数据传输。如果延迟时间预算太紧张,那么显然就没有时间可以用来重试传输失败的数据包,也就需要禁用 ACK/NAK 协议。有趣的是,PCIe 的协议规范制定者显然没有考虑到这一点,因为并没有设计用来禁用 ACK/NAK 协议的配置 bit,也没有设计配置 bit 用来决定如何处理那些本来会被重传而现在不会被重传的数据包。因此,禁用 ACK/NAK 协议需要使用一些非标准机制,例如 Vendor-specific 寄存器。
如果没有足够的时间用于重传,那么目的方可能就会简单的将损坏的数据包丢弃。另一个选择是就直接使用损坏、错误的所有数据包。对于一些使用等时服务支持的应用来说,使用损坏数据包的这种操作并没有听起来这么不可接受。例如,视频流中的错误可能会导致显示器偶尔出现故障闪烁,但是这个风险被认为是可以接受的。
不同于上面的情况,如果在服务间隔(Service Interval)中,有足够的时间用于重传,那么就可以通过添加一个计时器的方式来给重试延迟设置一个上限,这个计时器会一直记录时间直到当前 SI 结束,可以使用它来决定是否可以进行重试操作。当然,错误情况不应该很频繁的出现,所以这种方式对于偶尔出现的传输错误来说是足够的,并且同时也可以保持等时的时间规划。